
Самая мощная видеокарта tesla
Добавил пользователь Дмитрий К. Обновлено: 19.09.2024
NVIDIA начала продажи Tesla K20Xm 12 ноября 2012 по рекомендованной цене 7,699$. Это десктопная видеокарта на архитектуре Kepler и техпроцессе 28 нм, в первую очередь рассчитанная на дизайнеров. На ней установлено 6 Гб памяти GDDR5 на частоте 5.2 ГГц, и вкупе с 384-битным интерфейсом это создает пропускную способность 249.6 Гб/с.
С точки зрения совместимости это двухслотовая карта, подключаемая по интерфейсу PCIe 3.0 x16. Длина референсной версии – 267 мм. Для подключения не требуется дополнительный кабель питания, а потребляемая мощность – 235 Вт.
Она обеспечивает слабую производительность в тестах и играх на уровне
от лидера, которым является NVIDIA GeForce RTX 3090 Ti.
Общая информация
Сведения о типе (для десктопов или ноутбуков) и архитектуре Tesla K20Xm, а также о времени начала продаж и стоимости на тот момент.
| Место в рейтинге производительности | 251 |
| Архитектура | Kepler |
| Графический процессор | GK110 |
| Тип | Для рабочих станций |
| Дата выхода | 12 ноября 2012 (9 лет назад) |
| Цена на момент выхода | 7,699$ |
Характеристики
Общие параметры Tesla K20Xm: количество шейдеров, частота видеоядра, техпроцесс, скорость текстурирования и вычислений. Они косвенным образом говорят о производительности Tesla K20Xm, но для точной оценки необходимо рассматривать результаты бенчмарков и игровых тестов.
| Количество потоковых процессоров | 2688 | из 18432 (AD102) |
| Частота ядра | 732 МГц | из 2610 (Radeon RX 6500 XT) |
| Количество транзисторов | 7,080 млн | из 14400 (GeForce GTX 1080 SLI (мобильная)) |
| Технологический процесс | 28 нм | из 5 (Apple M1 GPU) |
| Энергопотребление (TDP) | 235 Вт | из 900 (Tesla S2050) |
| Скорость текстурирования | 164.0 | из 939.8 (H100 SXM5) |
| Производительность с плавающей точкой | 3,935 gflops | из 16384 (Radeon Pro Duo) |
Совместимость и размеры
Параметры, отвечающие за совместимость Tesla K20Xm с остальными компонентами компьютера. Пригодятся например при выборе конфигурации будущего компьютера или для апгрейда существующего. Для десктопных видеокарт это интерфейс и шина подключения (совместимость с материнской платой), физические размеры видеокарты (совместимость с материнской платой и корпусом), дополнительные разъемы питания (совместимость с блоком питания).
| Интерфейс | PCIe 3.0 x16 |
| Длина | 267 мм |
Оперативная память
Параметры установленной на Tesla K20Xm памяти - тип, объем, шина, частота и пропускная способность. Для встроенных в процессор видеокарт, не имеющих собственной памяти, используется разделяемая - часть оперативной памяти.
| Тип памяти | GDDR5 | |
| Максимальный объём памяти | 6 Гб | из 128 (Radeon Instinct MI250X) |
| Ширина шины памяти | 384 бит | из 8192 (Radeon Instinct MI250X) |
| Частота памяти | 5200 МГц | из 19500 (GeForce RTX 3090) |
| Пропускная способность памяти | 249.6 Гб/с | из 14400 (Radeon R7 M260) |
Видеовыходы
Перечисляются имеющиеся на Tesla K20Xm видеоразъемы. Как правило, этот раздел актуален только для десктопных референсных видеокарт, так как для ноутбучных наличие тех или иных видеовыходов зависит от модели ноутбука.
| Видеоразъемы | No outputs |
Поддержка API
Перечислены поддерживаемые Tesla K20Xm API, включая их версии.
| DirectX | 12 (11_0) |
| Шейдерная модель | 5.1 |
| OpenGL | 4.6 |
| OpenCL | 1.2 |
| Vulkan | 1.1.126 |
| CUDA | 3.5 |
Тесты в бенчмарках
Это результаты тестов Tesla K20Xm на производительность рендеринга в неигровых бенчмарках. Общий балл выставляется от 0 до 100, где 100 соответствует самой быстрой на данный момент видеокарте.
Общая производительность в тестах
Это наш суммарный рейтинг производительности. Мы регулярно улучшаем наши алгоритмы, но если вы обнаружите какие-то несоответствия, не стесняйтесь высказываться в разделе комментариев, мы обычно быстро устраняем проблемы.
Benchmark coverage: 25%
Это очень распространенный бенчмарк, входящий в состав пакета Passmark PerformanceTest. Он дает видеокарте тщательную оценку, производя четыре отдельных теста для Direct3D версий 9, 10, 11 и 12 (последний по возможности делается в разрешении 4K), и еще несколько тестов, использующих DirectCompute.
Вычислительные ускорители NVIDIA Tesla прочно заняли своё место везде, где требуется высокая вычислительная производительность: от биржевого анализа до научных расчётов. Ими комплектуются специальные серверы, на их базе строятся вычислительные суперкластеры. Секрет успеха NVIDIA в этой области — поддержка всех современных как закрытых (CUDA), так и открытых технологий (OpenCL, DirectCompute). И в одной из предыдущих новостей мы уже сообщали, что компания готовит к запуску новые модели ускорителей Tesla, как на базе новой архитектуры Maxwell, так и на основе проверенной временем архитектуры Kepler. Особняком в этом списке стояла модель Tesla K80, которая должна была стать вторым двухпроцессорным вычислительным ускорителем NVIDIA после устаревшего D870.

NVIDIA Tesla K80 не имеет вентилятора

Самый быстрый ускоритель научных расчётов

Быстрая межпроцессорная шина гарантирует отсутствие узких мест
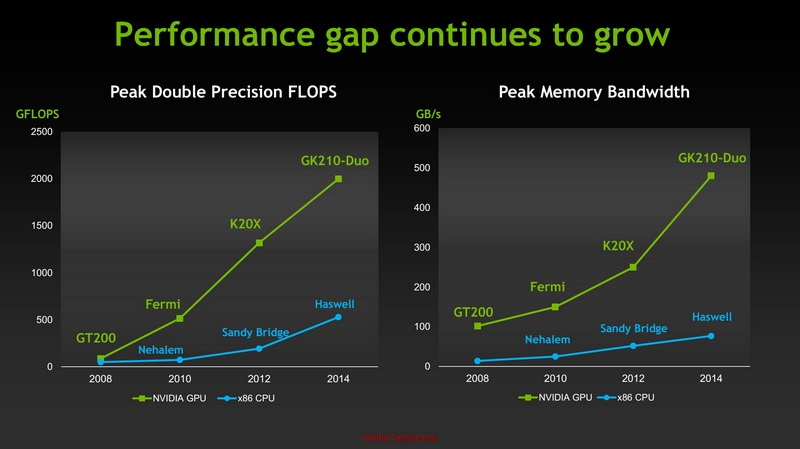
Преимущества GPGPU очевидны

Широкий спектр задач и высокая производительность. У традиционных ЦП нет шансов
А между тем, технологии не стоят на месте, и очень интересно будет взглянуть на будущих монстров Tesla на базе GM200.


Обе новинки предлагаются в двухслотовом исполнении с пассивным охлаждением на печатных платах под шину PCI Express 3.0 x16.

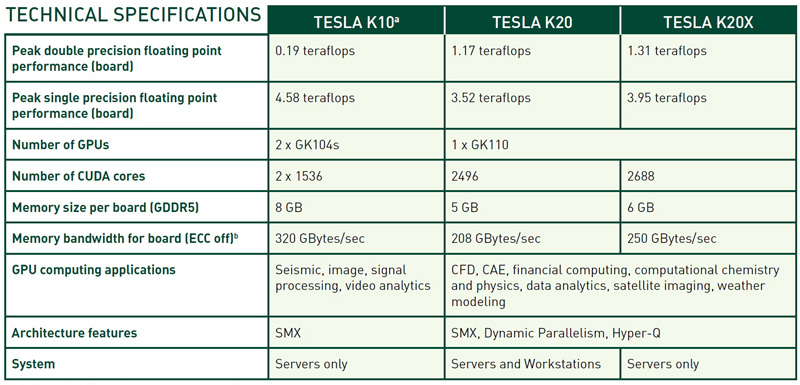
Флагман Tesla K20X с 2688 ядрами CUDA, как заявлено, обеспечивает самый высокий из возможных ныне уровень производительности для одного GPU, а именно 3,95 терафлопс в вычислениях с одинарной точностью и 1,31 терафлопс в вычислениях с двойной точностью. На его борту присутствует 6144 Мбайт памяти GDDR5 с 384-битным интерфейсом. Частота ядра/памяти равна 732/5200 МГц. Максимальная потребляемая мощность достигает 235 Вт.
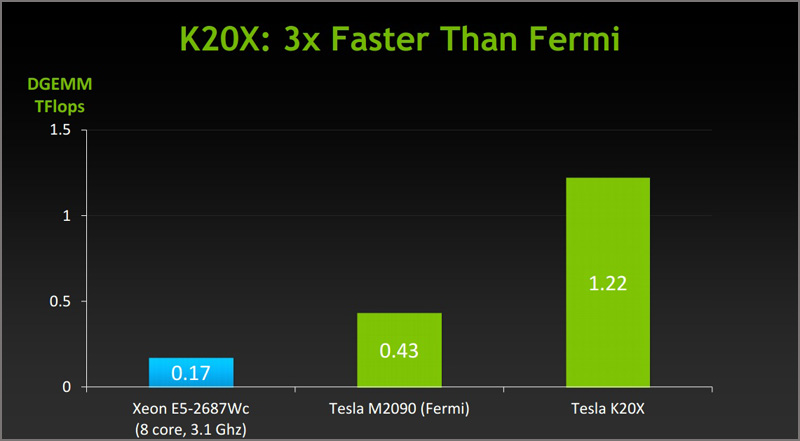
В свою очередь Tesla K20 c 2496 ядрами CUDA характеризуется производительностью 3,52 терафлопс в вычислениях одинарной точности и 1,17 терафлопс в вычислениях с двойной точностью. Видеокарта получила 5120 Мбайт памяти GDDR5 с 320-битным интерфейсом, функционирует на частотах 706/5200 МГц (ядро/память) и во время работы потребляет не более 225 Вт энергии.
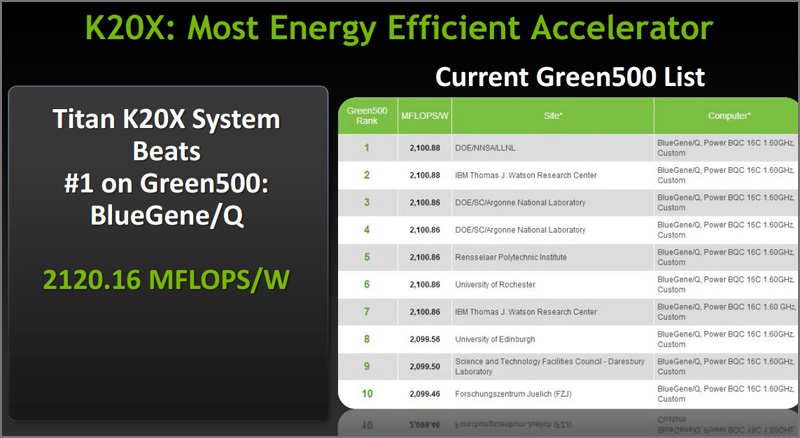
По словам разработчиков, 18688 ускорителей Tesla K20X легли в основу суперкомпьютера Titan, который, согласно новой редакции рейтинга TOP500, является на сегодняшний день самым мощным в мире. Данный суперкомпьютер расположен в Национальной Лаборатории Окриджа, штат Теннесси. Он стал новым лидером мирового рейтинга суперкомпьютеров с результатом в 17,59 петафлопс в бенчмарке LINPACK, сместив на этой позиции систему Sequoia из Ливерморской Национальной Лаборатории им. Лоуренса.

Попутно отмечается, что графический адаптер Tesla K20X отличается втрое меньшим энергопотреблением в сравнении с предыдущим поколением ускорителей NVIDIA и ещё больше увеличивает разрыв в производительности между GPU и CPU. Таким образом, суперкомпьютер Titan обеспечивает 2142,77 мегафлопс на Ватт и тем самым превосходит по энергоэффективности лидера последней версии списка самых экономичных суперкомпьютеров Green500.
Создатели акцентируют внимание и на том, что модель Tesla K20X в сочетании с CPU поколения Sandy Bridge от Intel способна ускорять многие приложения более чем в 10 раз. Например, MATLAB (инженерия) – в 18,1 раза, Chroma (физика) – в 17,9 раз, SPECFEM3D (землеведение) – в 10,5 раз, AMBER (молекулярная динамика) – в 8,2 раза.
Напоследок сообщим, что описанные выше видеокарты уже поставляются и доступны в составе решений от ведущих производителей серверов, включая Appro, ASUS, Cray, Eurotech, Fujitsu, HP, IBM, Quanta Computer, SGI, Supermicro, T-Platforms и Tyan, а также у партнёров-реселлеров NVIDIA.
Поиск полезной информации, которая скрыта в огромных объемах данных, может кардинально изменить целые отрасли, начиная от персонализированного подхода к лечению рака и заканчивая созданием виртуальных помощников, способных свободно общаться с человеком, и прогнозированием крупных ураганов.
NVIDIA ® Tesla ® V100 с тензорными ядрами – самый технически продвинутый в мире GPU для дата-центров, предназначенный для ускорения искусственного интеллекта, HPC, наука о данных и графики. Созданный на основе архитектуры NVIDIA Volta, он доступен в конфигурации с 16 или 32ГБ памяти и обеспечивает производительность на уровне 100 CPU. Это дает ученым, исследователям и инженерам возможность справляться с задачами, решение которых ранее было невозможно.
Работайте в приложениях для ИИ и НРС в виртуальной среде, обеспечив безопасность и простое управление при помощи ПО NVIDIA Virtual Compute Server (vCS).
Тренировка алгоритмов искусственного интеллекта
Ученые берутся за все более сложные задачи, начиная от распознавания речи и обучения виртуальных ассистентов и заканчивая обнаружением дорожной разметки, и обучением беспилотных автомобилей вождению. Решение подобного рода задач требует обучения экспоненциально более сложных моделей нейронных сетей в сжатые сроки.
Оснащенный 43 тыс. ядер Tensor, Tesla V100 – это первый ускоритель, преодолевший барьер производительности в 100 тера-операций в секунду (TOPS) в задачах глубокого обучения. Второе поколение технологии NVIDIA NVLink™ соединяет несколько графических ускорителей V100, обеспечивая пропускную способность в 160 ГБ/с и позволяя создавать самые мощные вычислительные серверы. Модели, обучение которых занимало недели на системах предыдущего поколения, теперь можно натренировать всего за несколько дней. Благодаря такому серьезному сокращению времени, затрачиваемого на тренировку алгоритмов, искусственный интеллект поможет решить самовершенно новые проблемы.
Инференс
Чтобы открыть нам доступ к актуальной информации, сервисам и продуктам, компании начали использовать искусственный интеллект. Однако удовлетворение потребностей пользователей – сложная задача. К примеру, по оценкам крупнейших компаний с гипермасштабируемой инфраструктурой, им придется вдвое увеличить быстродействие своих дата-центров, если каждый пользователь будет пользоваться их сервисами распознавания речи всего по три минуты в день.
Ускоритель Tesla V100 создан для обеспечения максимальной производительности в существующих сверхмасштабируемых дата-центрах. Один сервер, оснащенный Tesla V100 GPU и потребляющий 13 кВт энергии, обеспечивает в задачах инференса такую же производительность, как 30 CPU-серверов. Подобный скачок производительности и энергоэффективности способствует расширению масштабов применения сервисов с искусственным интеллектом.
Высокопроизводительные вычисления
HPC – фундаментальная опора современной науки. Начиная от прогнозирования погоды и создания новых лекарств и заканчивая поиском источников энергии, ученые постоянно используют большие вычислительные системы для моделирования нашего мира и прогнозирования событий в нем. Искусственный интеллект расширяет возможности HPC, позволяя ученым анализировать большие объемы данных и добывая полезную информацию там, где одни симуляции не могут предоставить полную картину происходящего.
Графический ускоритель Tesla V100 создан, чтобы обеспечить слияние HPC и искусственного интеллекта. Это решение для HPC-систем, которое отлично проявит себя как в вычислениях для проведения симуляций, так и обработке данных для извечения из них полезной информации. Благодаря объединению в одной архитектуре ядер CUDA и Tensor, сервер, оснащенный графическими ускорителями Tesla V100, может заменить сотни традиционных CPU-серверов, выполняя традиционные задачи HPC и искусственного интеллекта. Теперь каждый ученый может позволить себе суперкомпьютер, который поможет в решении самых сложных проблем.
На конференции SC12 Supercomputing в Солт-Лейк-Сити NVIDIA представила вычислительные карты для серверов и рабочих станций Tesla K20 и K20X на основе GPU GK110. Две версии, о которых мы поговорим ниже чуть подробнее, и объясняют путаницу, которая существовала в последние недели вокруг Tesla K20. Изначально поставщик стоечных серверов на GPU сообщил, что карты NVIDIA Tesla K20 будут использовать GK110 с 13 кластерами SMX, каждый со 192 ядрами CUDA, что дает 2496 ядер CUDA в общей сложности. Вскоре на открытии суперкомпьютера Titanium было указано на 2688 ядер CUDA, что указывает на 14 кластеров SMX. И существование двух версий карт объясняет подобный дуализм.

Tesla K20 на основе GK110
Tesla K20X - новая high-end модель для вычислений на GPU, ускоритель ориентирован исключительно на серверы. Чуть менее мощная карта Tesla K20 нацелена и на серверы, и на рабочие станции.
| GF110 Tesla M2090 | GK104 Tesla K10 | GK110 Tesla K20 | GK110 Tesla K20X | |
| Техпроцесс | 40 нм | 28 нм | 28 нм | 28 нм |
| Число транзисторов | 3 млрд. | 2x 3,54 млрд. | 7,1 млрд. | 7,1 млрд. |
| Техпроцесс | 530 мм² | 294 мм² | предполож. 600 мм² | предполож. 600 мм² |
| TDP | 225 Вт | 225 Вт | 225 Вт | 235 Вт |
| Тактовая частота GPU | 1300 МГц | 2x 745 МГц | - МГц | - МГц |
| Тактовая частота памяти | 463 МГц | 625 МГц | - МГц | - МГц |
| Тип памяти | GDDR5-ECC | GDDR5-ECC | GDDR5-ECC | GDDR5-ECC |
| Объём памяти | 6144 Мбайт | 8192 Мбайт | 5120 Мбайт | 6144 Мбайт |
| Ширина шины памяти | 384 бит | 256 бит | 320 бит | 384 бит |
| Пропускная способность памяти | 177 Гбайт/с | 2x 160 Гбайт/с | 208 Гбайт/с | 250 Гбайт/с |
| Потоковые процессоры | 512 (1D) | 2x 1536 (1D) | 2496 (1D) | 2688 (1D) |
| Кэш L1 | 64 кбайт | 64 кбайт | 64 кбайт | 64 кбайт |
| Кэш L2 | 768 кбайт | 512 кбайт | 1,5 Мбайт | 1,5 Мбайт |
| ECC | Память и кэши | Только память | Память и кэши | Память и кэши |
| FP64 | 1/2 FP32 | 1/24 FP32 | 1/3 FP32 | 1/3 FP32 |
| Одиночная точность | 1,33 TFlops | 4,58 TFlops | 3,52 TFlops | 3,95 TFlops |
| Двойная точность | 0,66 TFlops | 0,19 TFlops | 1,17 TFlops | 1,31 TFlops |
Огромный прирост производительности в вычислениях с двойной точностью и скромный прирост производительности с одинарной точностью можно объяснить смещением акцента с FP32 на FP64. Графический процессор GK110 стал первым чипом NVIDIA, ориентированным полностью на профессиональный рынок и сферы HPC (High Performance Computing). Карта Tesla K10 базируется на двух GPU GK104, которые относятся к первому поколению "Kepler" и ориентированы, в том числе, и на GPU GeForce, а в рендеринге производительность с одинарной точность играет решающую роль. Рейтинг производительности с одинарной точностью по отношению к двойной точности был снижен с 1/2 до 1/24. Наконец, у GK104 технологией ECC защищается только оперативная память, но не кэши.

Диаграмма GK110
Для получения более высокой производительности с двойной точностью, NVIDIA установила 64 ядра Floating Point на кластер SMX, у GK104 использовалось только восемь подобных ядер на кластер. Вместе с увеличением количества кластеров данный шаг привел к значительному приросту по производительности с двойной точностью. NVIDIA также опирается на свою скалярную архитектур "Superscalar Dispatch Method", которая появилась в GF104 и гарантирует более защищённые от ошибок вычисления. Эта архитектура опирается на параллелизм на уровне потоков Thread Level Parallelism (TLP) и параллелизм на уровне инструкций Instruction Level Parallelism (ILP).

Диаграмма кластера GK110 SMX
Производительность вычислений с двойной точностью была увеличения некоторыми изменениями в регистрах. Число регистров на кластеры SMX осталось прежним 65 536 по сравнению с GK104, но на поток GK110 обеспечивает доступ к 255 регистрам - в отличие от только 63 у GK104.
Как мы уже упоминали, интерфейс памяти стал шире, теперь он состоит из шести 64-битных блоков, которые вместе обеспечивают 384-битный интерфейс. В отличие от GK104, технология ECC защищает не только видеопамять, но и кэши L1 и L2. Поскольку определение ошибок подразумевает выполнение некоторых дополнительных вычислений, NVIDIA снизила вычислительные потери благодаря внутренней оптимизации до 66 процентов.
Hyper-Q и динамический параллелизм остались и в GK110.
Hyper-Q:
В случае архитектуры "Fermi" GPU могли работать только с одной рабочей очередью команд и данных, но в случае "Kepler" ситуация уже отличается.

Hyper-Q в сравнении
Одновременно с GPU "Kepler" могут работать до 32 физических ядер CPU. Конечно, данное ограничение не присутствует на программном уровне в интерфейсах DirectX 11, и несколько потоков могут выполняться одновременно, но передача данных и команд на GPU всё равно выполнялась последовательно. Благодаря поддержке Hyper-Q в будущем можно будет передавать данные параллельно.

Последовательное выполнение команд без Hyper-Q
Без поддержки Hyper-Q данные и команды передаются последовательно, загрузка GPU в данном случае не является оптимальной.

Выполнение команд с Hyper-Q
С помощью Hyper-Q данные и команды 32 физических ядер передаются одновременно. Это приводит не только к лучшему использованию GPU, но и к тому, что выполненные вычисления могут обрабатываться быстрее.
Кроме того, теперь множество GPU в системе могут напрямую связываться друг с другом. Технология "GPU Direct" как раз позволяет GPU "Kepler" связываться друг с другом даже по сети - обращение к CPU и памяти теперь уже не требуется.
Dynamic Parallelism:
Команды и данные, которые поставляются на GPU, могут быть взаимозависимыми (например, если расчеты зависят от результатов других вычислений), таким образом, части разных потоков могут блокироваться от выполнения на GPU некоторый промежуток времени. NVIDIA постаралась внести и улучшения обработки подобных ситуаций в интерфейс CUDA.

Dynamic Parallelism
Технология Dynamic Parallelism на GPU может решать подобные проблемы зависимости. Впрочем, от программистов тоже требуются усилия, поскольку им следует учитывать неравномерности обработки GPU и запросы из памяти. Если созданные потоки превысят возможности доступной памяти GPU, то будет проводиться обращение через шину памяти PCI Express, что может вновь замедлить весь процесс.

Dynamic Parallelism
GPU самостоятельно определяет, в каких пропорциях он будет допускать существование зависимостей. Всё это позволит Nvidia избежать сценариев, ограничивающих производительность.
Эффективность энергопотребления:
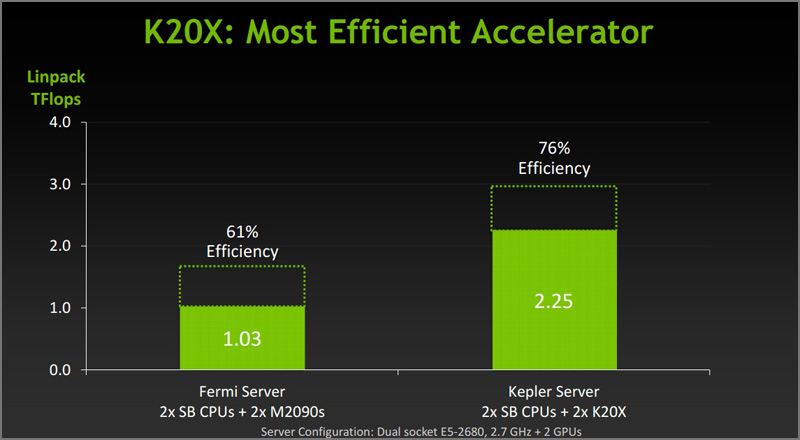
В случае NVIDIA Tesla K20 и K20X мы получаем отличные результаты по эффективности энергопотребления. Если вы взглянете на список Green500, в котором компьютеры приведены по рейтингу эффективности энергопотребления, то на одном из первых мест находится BlueGene/Q с 16 ядрами на 1,6 ГГц и вычислительной производительностью около 2100 мегафлопов на ватт. В случае системы NVIDIA Tesla K20X мы получаем около 2250 мегафлопов на ватт. А цена такого решения ещё и в четыре раза ниже.
Использование в суперкомпьютере Titan:
Вычислительные ускорители Tesla K20X используются в суперкомпьютере Titan в Окриджской национальной лаборатории (штат Теннеси, США). Установленная система достигает пиковой производительности 27 петафлопов. Суперкомпьютер состоит из 18 688 GPU NVIDIA Tesla K20X и такого же количества 16-ядерных процессоров AMD (Opteron 6274). Как можно догадаться, Titan состоит из 18 688 узлов, которые объединены в 200 ячеек. На каждый узел доступно 32 Гбайт памяти, что даёт общую ёмкость оперативной памяти 710 терабайт.

Конкуренты:
Вчера утром AMD объявила новые вычислительные ускорители FirePro S10000 на основе двух GPU Tahiti Pro. Мы опубликовали новость и сравнение теоретической производительности, но в тот момент карты K20X и K20 ещё не были официально объявлены.
| Модель | AMD FirePro S10000 | NVIDIA Tesla K20X | NVIDIA Tesla K20 | NVIDIA Tesla K10 | NVIDIA Tesla M2090 |
| Одиночная точность | 5,91 TFlops | 3,95 TFlops | 3,52 TFlops | 4,58 TFLops | 1,33 TFlops |
| Двойная точность | 1,48 TFlops | 1,31 TFlops | 1,17 TFlops | 0,19 TFlops | 0,67 TFlops |
По чистой теоретической производительности вычислительный ускоритель AMD FirePro S10000 обгоняет конкурентов NVIDIA, будь то GK104 или GK110. Но следует учитывать, что AMD для FirePro S10000 указывает максимальное энергопотребление 335 Вт, в то время как NVIDIA K20X отличается энергопотреблением всего 235 Вт. Кроме того, NVIDIA нацелила GK104 и GK110 на другие сферы применения, что можно видеть по соотношениям производительности с одинарной и двойной точностью.
Читайте также: